Skunk Works

The first thing we’re doing to test our approach to stylized production in Unreal is testing it out with an existing project, in this case the Monkey project me and Chris worked on for Vintata in 2016.
Here’s the original:
And here’s a new version, remade in Unreal:
...and proof that it’s all real-time:
The two versions aren’t visually identical--you may note the lack of fur tufts on the tail in the Unreal version, for instance, and the Unreal version has somewhat wiggly two-tones as we haven’t implemented any normal adjustments yet—but they’re very close in process. Except, of course, that the Unreal version is vastly faster to assemble and tweak.
There are two major things I wanted to accomplish with this stage of the pipeline. The first is to be able to build up a shot from an user-defined set of compositing passes, just as we would if we were rendering out passes from Maya and using a compositing app. The second is to be able to have a separate composite per-shot, so that we can accommodate per-shot tuning of the composite and shot-specific elements, and still be able to see multiple shots in Sequencer in real time.
Unreal already has a lot of the machinery needed for these goals built in. Composure, Unreal’s real-time compositing plug-in, lets you establish render passes (called “elements” in Composure) that will render any set of actors in the scene, and you can then use the extensive set of shader nodes in Unreal’s material editor to create compositing layers (called “passes” in Composure, which I imagine to be a clever tribute to Abbott and Costello). And Sequencer allows you to make any actor a “spawnable,” which will spawn into the scene just for that shot and vanish when it is not needed. This is a very strange way of thinking about scene assembly from a DCC perspective--imagine Maya was loading and unloading references during playback!--but makes perfect sense from the perspective of a game engine, which of course must be able to spawn alien zombie mercenaries at any time and then remove them after you have mercilessly slaughtered them. Since you can do this with any actor, including cameras and lights, this lets you have a lot of control over the specific contents of any shot.
However, there are a number of ways in which the default machinery falls short of what we need for this workflow. Composure allows you to create elements that render any set of actors in the scene from any camera, but it offers no control over how those actors are rendered. This makes essential concepts like separate light and shadow passes impossible with the default system. And while spawning and de-spawning most types of actors through sequencer works great, doing it with Composure elements breaks the links between a composite and the elements that contribute to it, so that’s not a viable workflow when combined with Composure. Leaving multiple composites in the level isn’t a good plan either, as elements will impact performance even if their output isn’t currently being viewed, and you probably don’t want about a million elements clogging up your level anyway.
Luckily, Unreal is also a game engine, which means being able to easily modify the behavior of any actor is sort of it’s point. This makes it surprisingly easy to come up with hacky solutions for these problems, though more robust ones would be more difficult, and possibly require forking the engine. For the moment, we’ve decided to stick with hacky solutions, and evaluate whether more robust ones are necessary as we go.
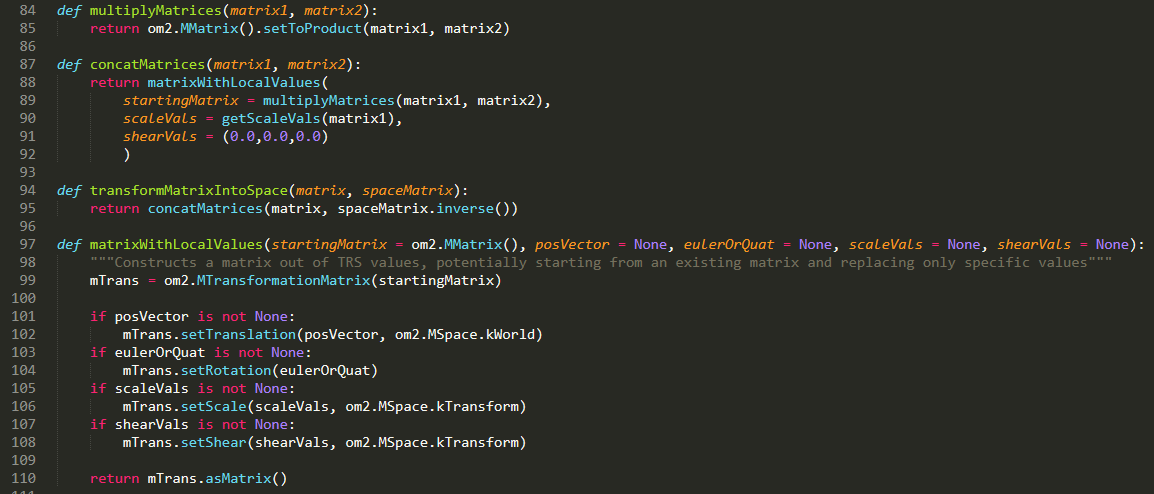
Because the Composure “CG Layer” element class is a Blueprint, it was very easy for me to get access to its inner workings so that I could insert something immediately before and after the element renders. One possible way to use this ability would be to assign a specified material to all the actors being rendered by the element, and then reassign back to the original material immediately after the render finishes. This might work, but it would involve doing a lot of bookkeeping about what material was assigned to each actor. We decided, instead, to make an uber-material on which all the materials in the scene would be based. This material would already know what material settings it should display depending on what pass was currently being rendered.

The material has multiple Material Attributes sets, and it chooses which one to use to render the surface based off of global Material Parameters:
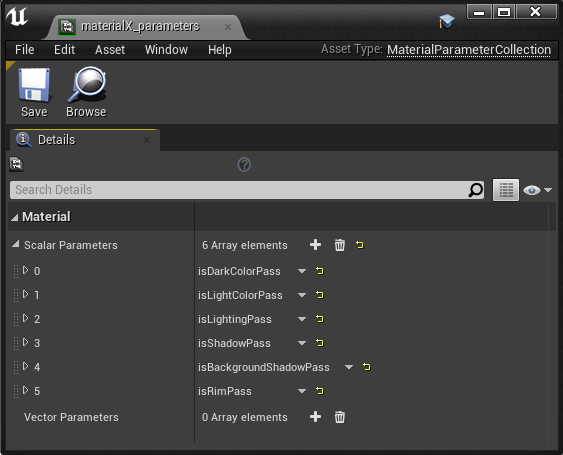
Because these parameters are global, I can have the composure element blueprint just change the parameter once and all materials will be affected. That’s as simple as this:

To control what lights apply to what elements, I added a variable to my special element class that lets the user link a light to it:

And any lights that are linked can have their visibility (and therefore their effect on the scene) swapped on and off (note that this function also calls the EnableMaterial function shown above when it’s done).

Then the lights and materials can be enabled and disabled immediately before and after rendering.

What you get from that is the ability to have separable lighting passes that render with a blank white surface, and give you a result you can manipulate in the composite and then combine with color passes.

How about shadows? One of the things I think is really important to be able to do for this kind of stylized rendering is have shadows that are projected from a different location then the light they occlude. That means being able to get separate shadow passes, something that’s quite common in an offline renderer that’s spitting out AOVs, but which doesn’t seem to be possible to get from Unreal without creating a custom shading model--you can access the passes Unreal writes to the gbuffer for it’s deferred rendering (such as normal and depth) directly with a SceneTexture node, but Unreal does not appear to create separate lighting and shadow passes in the gbuffer, so you’d need to create a shading model that does (or, more likely in this case, somehow outputs different results based on what element is currently being rendered, since SceneTexture does not appear to work correctly when used in a Composure pass. In fact, since we can’t get anything useful out of the gbuffer anyway and many passes use no lights at all, I switched from deferred to forward rendering for a significant improvement in frame rate).
Ultimately, creating a custom shading model may be the right thing to do, but it would take significant effort. For the moment, I’m instead using a hack so grotesque that I hesitate to describe it, lest it’s sheer ugliness drive the reader to acts of madness and despair. I create two lights, identical in every respect except that one is red and casts shadows, and the other is blue and does not. Then I take the resulting image and divide the red channel by the blue, thereby canceling out the lighting and extracting the shadow alone.
This is an abomination…but it does work.

Finally, I’ve created a set of “passes” using the material editor that can receive the results of each element. That includes the base composite that uses the lighting and shadow elements to blend between light and dark color elements with a user-definable two-tone threshold, and passes that allow the user to layer rims and additional shadow elements on top.

As an example, the base comp pass looks like this:

That gets us an almost final result, but we still have to deal with anti-aliasing. Unreal supports both FXAA and MSAA for in-engine anti-aliasing, but they’re not useful here--they’d be applied to each pass rather than the final composite, creating a variety of edge artifacts familiar to offline compositors, but which we do not want to have to manage here. In this case, working with unantialiased passes is actually a significant advantage. Using Unreal’s new high-quality offline rendering feature--which creates high-quality anti aliasing and motion blur by accumulating the image from multiple, slightly different renders--would also be an option, but unfortunately it does not seem to support Composure.
So instead, I’m simply rendering everything at 4k. Then, after the fact, I’m running FXAA on the frames in After Effects and reducing them back down to 1080p. The combination of FXAA and bicubic scaling produces pretty nice anti-aliasing, and while it does necessitate an offline pass on all rendered frames before they’re final, we can still see something that accurately represents every aspect of the final image other than anti-aliasing in real time.
To be honest, I’m not entirely comfortable with the level of hackery going on here. It reminds me far too much of the way rigging, as a field, has largely been built on top of ancient hacks used to kluge together the features that already existed in the software of the time into something that halfway worked—and how the entire field has been poisoned for decades by the legacy of those hacks. On the other hand, hacks are also how you get things done without a dedicated development team, and they’re often how you eventually get to something that is actually engineered well. It’s just always important to remember that your hacky solution has put you deep in technical debt, and be ready to put in the work to pull yourself out of it when you need a more robust solution instead of trying to spackle over the holes like rigging did.
Next time, we’ll talk about how to set this up for multiple shots in sequencer.